Multiprocessing#
Complex analytics in Python may require additional speedups that can be gained by using the Python multiprocessing library. Other libraries like web applications take advantage of multiprocessing to serve a large number of users. Because btrdb-python uses grpc under the hood, it is important to understand how to connect and reuse connections to the database in a multiprocess or multithread context.
The most critical thing to note is that btrdb.Connection objects are not thread or multiprocess-safe. This means that in your code you should use either a lock or a semaphore to share a single connection object or that each process or thread should create their own connection object and clean up after themselves when they are done using the connection.
Let’s take the following simple example: we want to perform a data quality analysis on 12 hour chunks of data for all the streams in our staging/sensors collection. If we have hundreds of sensor streams across many months, this job can be sped up dramatically by using multiprocessing. Instead of having a single process churning through the each chunk of data one at a time, several workers can process multiple data chunks simultanously using multiple CPU cores and taking advantage of other CPU scheduling optimizations.
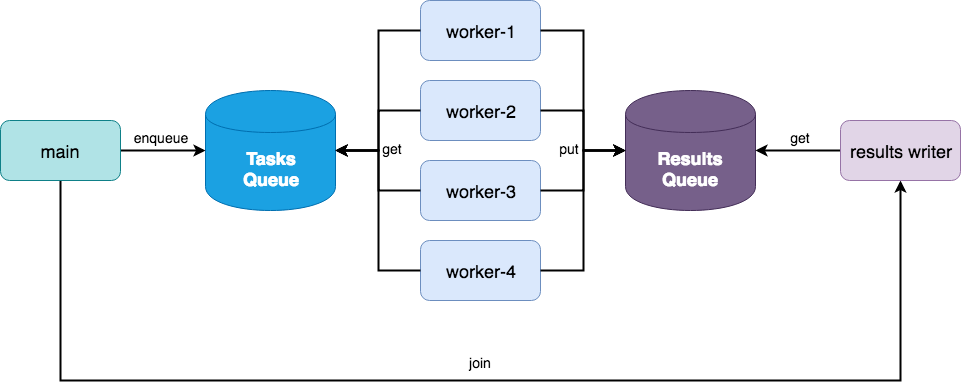
Fig. 1 A two queue multiprocessing architecture for data parallel processing.#
Consider the processing architecture shown in Fig. 1. At first glance, this architecture looks similar to the one used by multiprocessing.Pool, which is true. However, consider the following code:
import json
import math
import btrdb
import multiprocessing as mp
from btrdb.utils.timez import ns_delta
# This is just an example method
from qa import data_quality
def time_ranges(stream):
"""
Returns all 12 hour time ranges for the given stream
"""
earliest = stream.earliest()[0].time
latest = stream.latest()[0].time
hours = int(math.ceil((latest-earliest)/3.6e12))
for i in range(0, hours, 12):
start = earliest + ns_delta(hours=i)
end = start + ns_delta(hours=12)
yield start, end
def stream_quality(uuid):
"""
Connects to BTrDB and applies the data quality to 12 hour chunks
"""
# Connect to DB and get the stream and version
db = btrdb.connect()
stream = db.stream_from_uuid(uuid)
version = stream.version()
# Get the data quality scores for each 12 hour chunk of data
quality = []
for start, end in time_ranges(stream):
values = stream.values(start=start, end=end, version=version)
quality.append(data_quality(values))
# Return the quality scores
return json.dumps({"uuid": str(uuid), "version": version, "quality": quality})
if __name__ == "__main__":
# Get the list of streams to get scores for
db = btrdb.connect()
streams = db.streams_in_collection("staging/sensors")
# Create the multiprocessing pool and execute the analytic
pool = mp.Pool(processes=mp.cpu_count())
for result in pool.imap_unordered(stream_quality, [s.uuid for s in streams]):
print(result)
Let’s break this down quickly since this is a very common design pattern. First the time_ranges function gets the earliest and latest timestamp from a stream, then returns all 12 hour intervals between those two timestamps with no overlap. An imaginary stream_quality function takes a uuid for a stream, connects to the database and then applies the example data_quality method to all 12 hour chunks of data using the time_ranges method, returning a JSON string with the results.
The stream_quality function is our parallelizable function (e.g. computing the data quality for multiple streams at a time). Depending on how long the data_quality function takes to compute, we may also want to parallelize (stream, start, end) tuples.
If you would like features like a connection pool object (as other databases have) or multiprocessing helpers, please leave us a note in our GitHub issues!