BTrDB Explained#
The Berkeley Tree DataBase (BTrDB) is pronounced “Better DB”.
A next-gen timeseries database for dense, streaming telemetry.
Problem: Existing timeseries databases are poorly equipped for a new generation of ultra-fast sensor telemetry. Specifically, millions of high-precision power meters are to be deployed through the power grid to help analyze and prevent blackouts. Thus, new software must be built to facilitate the storage and analysis of its data.
Baseline: We need 1.4M inserts/second and 5x that in reads if we are to support 1000 micro-synchrophasors per server node. No timeseries database can do this.
Summary#
Goals: Develop a multi-resolution storage and query engine for many 100+ Hz streams at nanosecond precision—and operate at the full line rate of underlying network or storage infrastructure for affordable cluster sizes (less than six).
Developed at The University of California Berkeley, BTrDB offers new ways to support the aforementioned high throughput demands and allows efficient querying over large ranges.
Fast writes/reads
Measured on a 4-node cluster (large EC2 nodes):
53 million inserted values per second
119 million queried values per second
Fast analysis
In under 200ms, it can query a year of data at nanosecond-precision (2.1 trillion points) at any desired window—returning statistical summary points at any desired resolution (containing a min/max/mean per point).
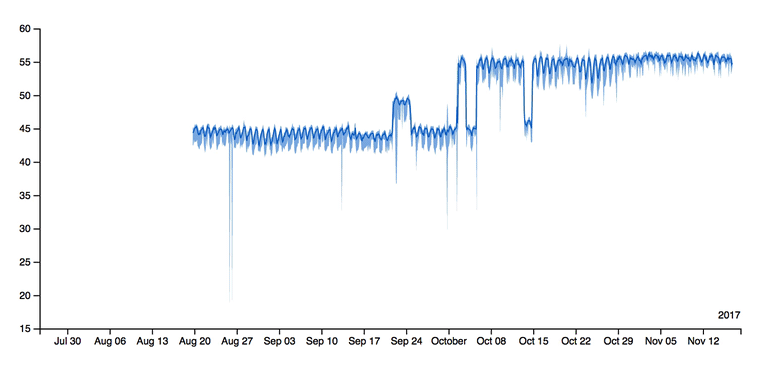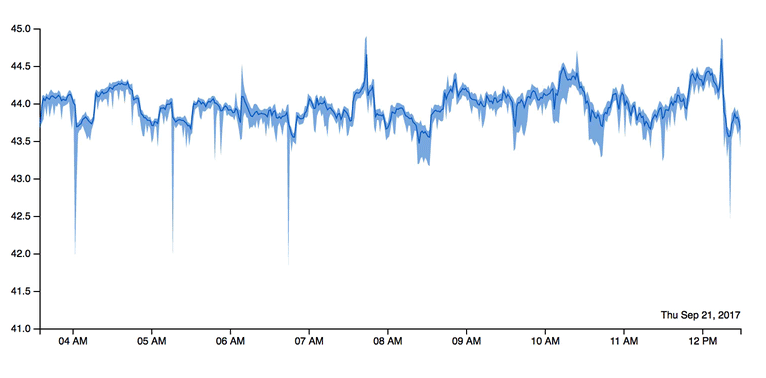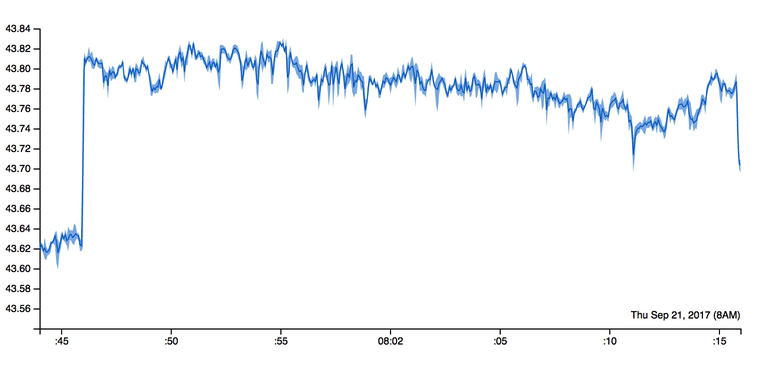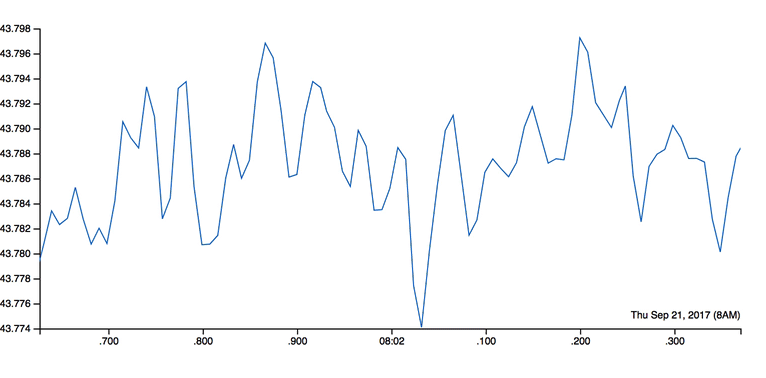
Fig. 2 BTrDB enables rapid timeseries queries to support analyses that zoom from years of data to nanosecond granularity smoothly, similar to how you might zoom into a street level view on Google Maps.#
High compression
Data is compressed by 2.93x—a significant improvement for high-precision nanosecond streams. To achieve this, a modified version of run-length encoding was created to encode the jitter of delta values rather than the delta values themselves. Incidentally, this outperforms the popular audio codec FLAC which was the original inspiration for this technique.
Efficient Versioning
Data is version-annotated to allow queries of data as it existed at a certain time. This allows reproducible query results that might otherwise change due to newer realtime data coming in. Structural sharing of data between versions is done to make this process as efficient as possible.
The Tree Structure#
BTrDB stores its data in a time-partitioned tree.
All nodes represent a given time slot. A node can describe all points within its time slot at a resolution corresponding to its depth in the tree.
The root node covers ~146 years. With a branching factor of 64, bottom nodes at ten levels down cover 4ns each.
level |
node width |
time granularity |
|---|---|---|
1 |
262 ns |
~146 years |
2 |
256 ns |
~2.28 years |
3 |
250 ns |
~13.03 days |
4 |
244 ns |
~4.88 hours |
5 |
238 ns |
~4.58 minutes |
6 |
232 ns |
~4.29 seconds |
7 |
226 ns |
~67.11 ms |
8 |
220 ns |
~1.05 ms |
9 |
214 ns |
~16.38 µs |
10 |
28 ns |
256 ns |
11 |
22 ns |
4 ns |
A node starts as a vector node, storing raw points in a vector of size 1024. This is considered a leaf node, since it does not point to any child nodes.:
┌─────────────────────────────────────────────────────────────────┐
│ │
│ VECTOR NODE │
│ (holds 1024 raw points) │
│ │
├─────────────────────────────────────────────────────────────────┤
│ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . │ <- raw points
└─────────────────────────────────────────────────────────────────┘
Once this vector is full and more points need to be inserted into its time slot, the node is converted to a core node by time-partitioning itself into 64 “statistical” points.:
┌─────────────────────────────────────────────────────────────────┐
│ │
│ CORE NODE │
│ (holds 64 statistical points) │
│ │
├─────────────────────────────────────────────────────────────────┤
│ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ │ <- stat points
└─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┘
▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ <- child node pointers
A statistical point represents a 1/64 slice of its parent’s time slot. It holds the min/max/mean/count of all points inside its time slot, and points to a new node holding extra details. When a vector node is first converted to a core node, the raw points are pushed into new vector nodes pointed to by the new statistical points.
level |
node width |
stat point width |
total nodes |
total stat points |
|---|---|---|---|---|
1 |
262 ns (~146 years) |
256 ns (~2.28 years) |
20 nodes |
26 points |
2 |
256 ns (~2.28 years) |
250 ns (~13.03 days) |
26 nodes |
212 points |
3 |
250 ns (~13.03 days) |
244 ns (~4.88 hours) |
212 nodes |
218 points |
4 |
244 ns (~4.88 hours) |
238 ns (~4.58 min) |
218 nodes |
224 points |
5 |
238 ns (~4.58 min) |
232 ns (~4.29 s) |
224 nodes |
230 points |
6 |
232 ns (~4.29 s) |
226 ns (~67.11 ms) |
230 nodes |
236 points |
7 |
226 ns (~67.11 ms) |
220 ns (~1.05 ms) |
236 nodes |
242 points |
8 |
220 ns (~1.05 ms) |
214 ns (~16.38 µs) |
242 nodes |
248 points |
9 |
214 ns (~16.38 µs) |
28 ns (256 ns) |
248 nodes |
254 points |
10 |
28 ns (256 ns) |
22 ns (4 ns) |
254 nodes |
260 points |
11 |
22 ns (4 ns) |
260 nodes |
The sampling rate of the data at different moments will determine how deep the tree will be during those slices of time. Regardless of the depth of the actual data, the time spent querying at some higher level (lower resolution) will remain fixed (quick) due to summaries provided by parent nodes.
…
Appendix#
The original version of this page can be found at:
This page is written based on the following sources: